publications
My publications by year in chronological order.
2025
2025
- Reading Recognition in the WildCharig Yang, Samiul Alam, Shakhrul Iman Siam, and 8 more authorsIn The Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025
- Benchmarking is Broken-Don’t Let AI Be Its Own JudgeZerui Cheng, Stella Wohnig, Ruchika Gupta, and 8 more authorsIn The Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025
2024
2024
- Artificial Intelligence of Things: A SurveyShakhrul Iman Siam, Hyunho Ahn, Li Liu, and 7 more authorsACM Trans. Sen. Netw., Aug 2024
The integration of the Internet of Things (IoT) and modern Artificial Intelligence (AI) has given rise to a new paradigm known as the Artificial Intelligence of Things (AIoT). In this survey, we provide a systematic and comprehensive review of AIoT research. We examine AIoT literature related to sensing, computing, and networking & communication, which form the three key components of AIoT. In addition to advancements in these areas, we review domain-specific AIoT systems that are designed for various important application domains. We have also created an accompanying GitHub repository, where we compile the papers included in this survey: https://github.com/AIoT-MLSys-Lab/AIoT-Survey. This repository will be actively maintained and updated with new research as it becomes available. As both IoT and AI become increasingly critical to our society, we believe AIoT is emerging as an essential research field at the intersection of IoT and modern AI. We hope this survey will serve as a valuable resource for those engaged in AIoT research and act as a catalyst for future explorations to bridge gaps and drive advancements in this exciting field.
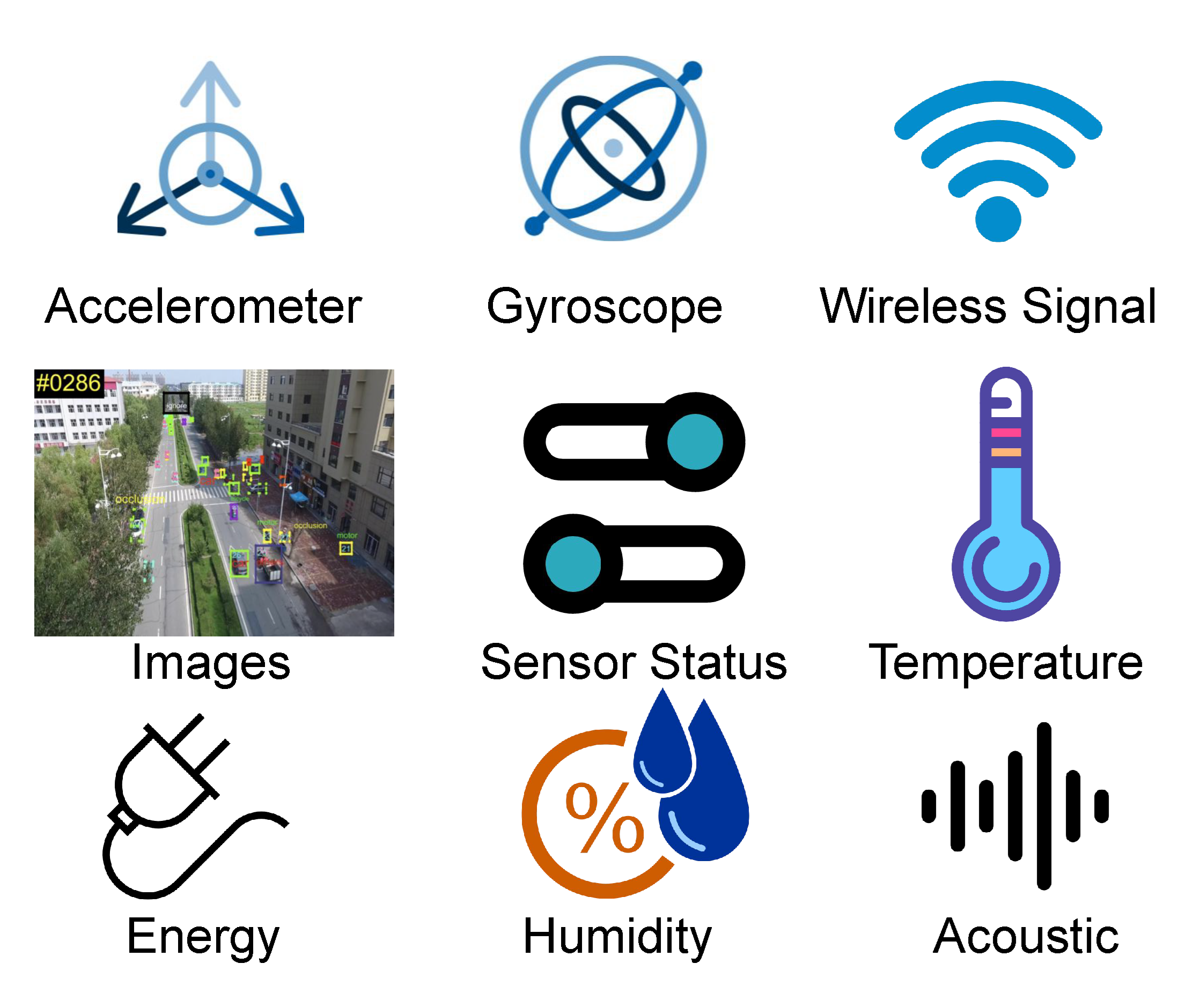 FedAIoT: A Federated Learning Benchmark for Artificial Intelligence of ThingsSamiul Alam, Tuo Zhang, Tiantian Feng, and 8 more authorsJournal of Data Centric Machine Learning, Aug 2024
FedAIoT: A Federated Learning Benchmark for Artificial Intelligence of ThingsSamiul Alam, Tuo Zhang, Tiantian Feng, and 8 more authorsJournal of Data Centric Machine Learning, Aug 2024There is a significant relevance of federated learning (FL) in the realm of Artificial Intelligence of Things (AIoT). However, most existing FL works are not conducted on datasets collected from authentic IoT devices that capture unique modalities and inherent challenges of IoT data. In this work, we introduce FedAIoT, an FL benchmark for AIoT to fill this critical gap. FedAIoT includes eight datatsets collected from a wide range of IoT devices. These datasets cover unique IoT modalities and target representative applications of AIoT. FedAIoT also includes a unified end-to-end FL framework for AIoT that simplifies benchmarking the performance of the datasets. Our benchmark results shed light on the opportunities and challenges of FL for AIoT. We hope FedAIoT could serve as an invaluable resource to foster advancements in the important field of FL for AIoT. The repository of FedAIoT is maintained at https://github.com/AIoT-MLSys-Lab/FedAIoT
- IoT in the Era of Generative AI: Vision and ChallengesXin Wang, Zhongwei Wan, Arvin Hekmati, and 4 more authorsarXiv preprint arXiv:2401.01923, Aug 2024
Equipped with sensing, networking, and computing capabilities, Internet of Things (IoT) such as smartphones, wearables, smart speakers, and household robots have been seamlessly weaved into our daily lives. Recent advancements in Generative AI exemplified by GPT, LLaMA, DALL-E, and Stable Difussion hold immense promise to push IoT to the next level. In this article, we share our vision and views on the benefits that Generative AI brings to IoT, and discuss some of the most important applications of Generative AI in IoT-related domains. Fully harnessing Generative AI in IoT is a complex challenge. We identify some of the most critical challenges including high resource demands of the Generative AI models, prompt engineering, on-device inference, offloading, on-device fine-tuning, federated learning, security, as well as development tools and benchmarks, and discuss current gaps as well as promising opportunities on enabling Generative AI for IoT. We hope this article can inspire new research on IoT in the era of Generative AI.
- Skin Conductance Response Artifact Reduction: Leveraging Accelerometer Noise Reference and Deep Breath DetectionMd Rafiul Amin, Samiul Alam, Saman Khazaei, and 2 more authorsIEEE Access, Aug 2024
Electrodermal activity (EDA) shows a significant correlation with activation of the autonomic nervous system (ANS) activation. Regular ambulatory monitoring via wearables and consequent inference of ANS activation has a wide range of applications tracking mental health. The real-world implementation of a closed-loop system to regulate one’s emotional state to improve their mental well-being requires an accurate and reliable estimation of ANS activation in ambulatory settings. However, the presence of motion artifacts in skin conductance (SC) data collected in ambulatory settings makes the analysis for such estimation unreliable. We propose a multi-rate adaptive filtering scheme to reduce motion artifacts in SC data that utilizes three-axis accelerometer data. We investigate four types of linear and nonlinear adaptive filters. We use both simulated and experimental data to investigate the performance of adaptive filters. Furthermore, we utilize the respiration signal to identify the probability of respiration-induced SC artifacts. Next, we use a Bayesian filter-based deconvolution approach to identify SC responses (SCRs) induced by underlying arousal events and deep breaths. Finally, we propose to use the respiration signal to separate the artifacts in SC due to deep breaths. Our results show that linear finite impulse response least squares recursive filters perform best among the four types of adaptive filters studied. We draw this conclusion by obtaining receiver operating characteristics of event-related SCRs detection with deconvolution after artifact reduction with different adaptive filters. Moreover, for all of our simulated and experimental datasets investigated in this study, we observe that the recursive least-squares filter always provides stable results. Additionally, our results show our ability to detect respiration-induced SCRs and the corresponding activation of ANS. The evaluation of adaptive filters shows the potential to utilize reference signals for successful artifact modeling and reduction. Effective artifact reduction will lead to reliable ANS activation monitoring and consequent robust implementation of a closed-loop wearable machine interface architecture to eventually improve one’s mental health.
 Unveiling productivity: The interplay of cognitive arousal and expressive typing in remote work with multi-state filteringSamiul Alam, Saman Khazaei, and Rose T FaghihPloS one, Aug 2024
Unveiling productivity: The interplay of cognitive arousal and expressive typing in remote work with multi-state filteringSamiul Alam, Saman Khazaei, and Rose T FaghihPloS one, Aug 2024Cognitive Arousal, frequently elicited by environmental stressors that exceed personal coping resources, manifests in measurable physiological markers, notably in galvanic skin responses. This effect is prominent in cognitive tasks such as composition, where fluctuations in these biomarkers correlate with individual expressiveness. It is crucial to understand the nexus between cognitive arousal and expressiveness. However, there has not been a concrete study that investigates this inter-relation concurrently. Addressing this, we introduce an innovative methodology for simultaneous monitoring of these elements. Our strategy employs Bayesian analysis in a multi-state filtering format to dissect psychomotor performance (captured through typing speed), galvanic skin response or skin conductance (SC), and heart rate variability (HRV). This integrative analysis facilitates the quantification of expressive behavior and arousal states. At the core, we deploy a state-space model connecting one latent psychological arousal condition to neural activities impacting sweating (inferred through SC responses) and another latent state to expressive behavior during typing. These states are concurrently evaluated with model parameters using an expectation-maximization algorithms approach. Assessments using both computer-simulated data and experimental data substantiate the validity of our approach. Outcomes display distinguishable latent state patterns in expressive typing and arousal across different computer software used in office management, offering profound implications for Human-Computer Interaction (HCI) and productivity analysis. This research marks a significant advancement in decoding human productivity dynamics, with extensive repercussions for optimizing performance in telecommuting scenarios.
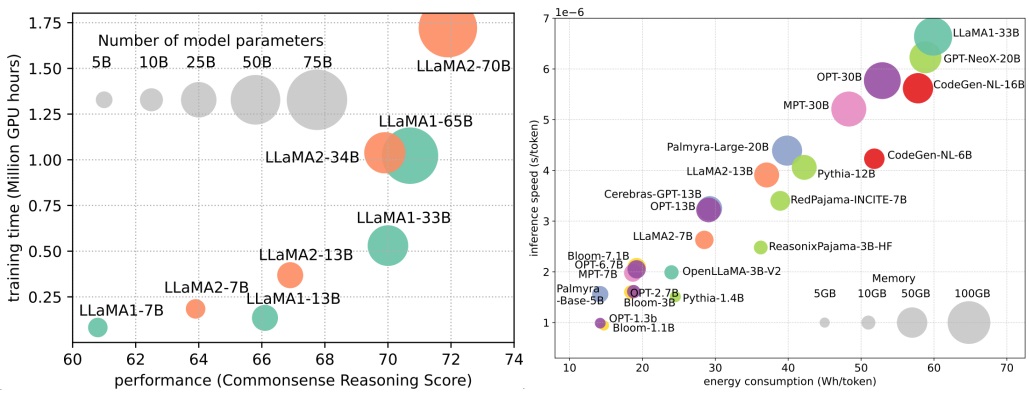 Efficient Large Language Models: A SurveyZhongwei Wan, Xin Wang, Che Liu, and 9 more authorsTransactions on Machine Learning Research, Aug 2024Survey Certification
Efficient Large Language Models: A SurveyZhongwei Wan, Xin Wang, Che Liu, and 9 more authorsTransactions on Machine Learning Research, Aug 2024Survey CertificationLarge Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding, language generation, and complex reasoning and have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we compile the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey, this https URL, and will actively maintain this repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.
2023
2023
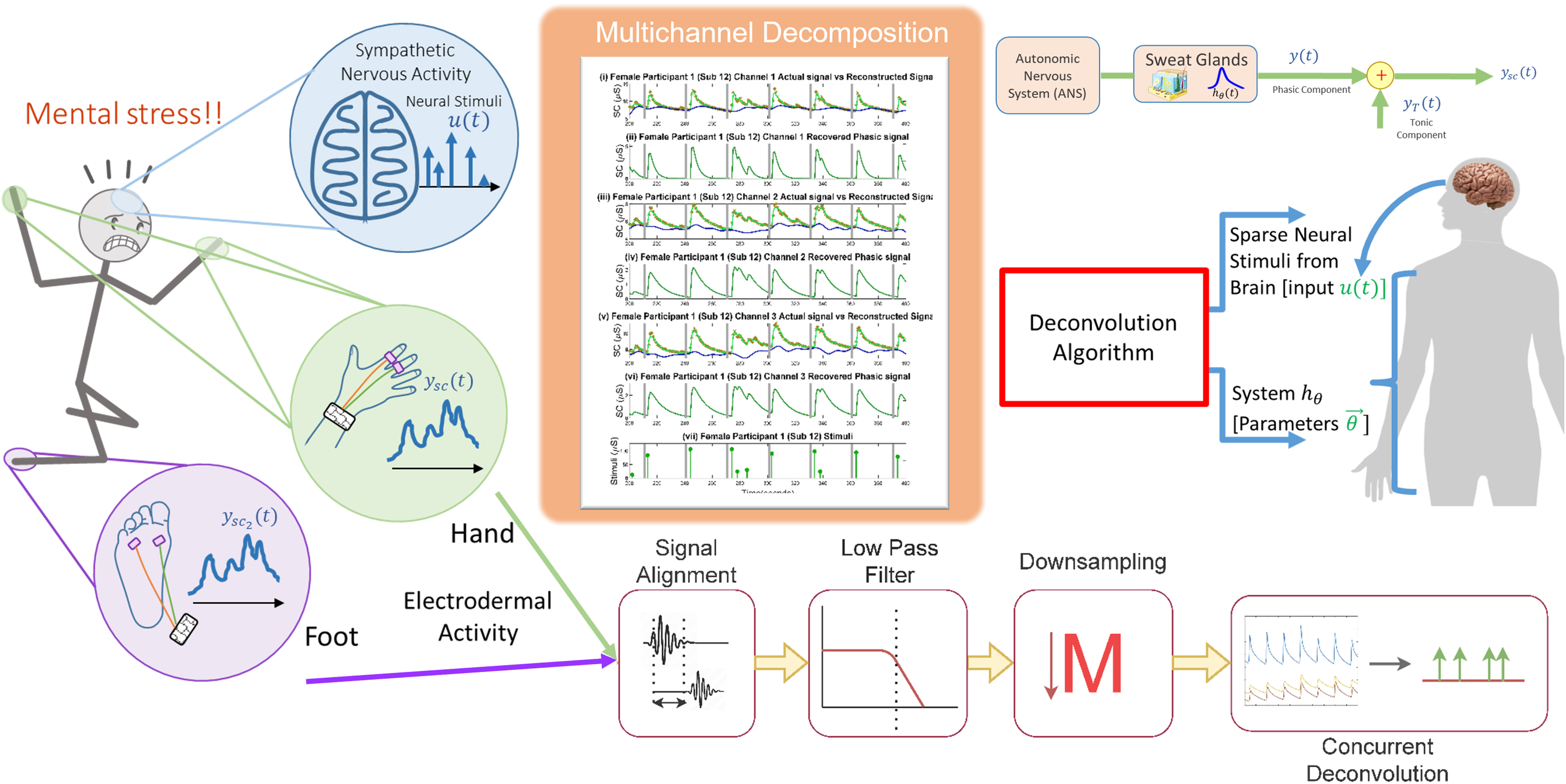 Sparse Multichannel Decomposition of Electrodermal Activity With Physiological PriorsSamiul Alam, Md. Rafiul Amin, and Rose T. FaghihIEEE Open Journal of Engineering in Medicine and Biology, Aug 2023
Sparse Multichannel Decomposition of Electrodermal Activity With Physiological PriorsSamiul Alam, Md. Rafiul Amin, and Rose T. FaghihIEEE Open Journal of Engineering in Medicine and Biology, Aug 2023Goal: Inferring autonomous nervous system (ANS) activity is a challenging issue and has critical applications in stress regulation. Sweat secretions caused by ANS activity influence the electrical conductance of the skin. Therefore, the variations in skin conductance (SC) measurements reflect the sudomotor nerve activity (SMNA) and can be used to infer the underlying ANS activity. These variations are strongly correlated with emotional arousal as well as thermoregulation. However, accurately recovering ANS activity and the corresponding state-space system from a single channel signal is difficult due to artifacts introduced by measurement noise. To minimize the impact of noise on inferring ANS activity, we utilize multiple channels of SC data. Methods: We model skin conductance using a second-order differential equation incorporating a time-shifted sparse impulse train input in combination with independent cubic basis spline functions. Finally, we develop a block coordinate descent method for SC signal decomposition by employing a generalized cross-validation sparse recovery approach while including physiological priors. Results: We analyze the experimental data to validate the performance of the proposed algorithm. We demonstrate its capacity to recover the ANS activations, the underlying physiological system parameters, and both tonic and phasic components. Finally, we present an overview of the algorithm’s comparative performance under varying conditions and configurations to substantiate its ability to accurately model ANS activity. Our results show that our algorithm performs better in terms of multiple metrics like noise performance, AUC score, the goodness of fit of reconstructed signal, and lower missing impulses compared with the single channel decomposition approach. Conclusion: In this study, we highlight the challenges and benefits of concurrent decomposition and deconvolution of multichannel SC signals.
- Gpt-fl: Generative pre-trained model-assisted federated learningTuo Zhang, Tiantian Feng, Samiul Alam, and 3 more authorsarXiv preprint arXiv:2306.02210, Aug 2023
- Federated Learning Benchmarks and Frameworks for Artificial Intelligence of ThingsSamiul AlamMichigan State University, Aug 2023
- FedAudio: A Federated Learning Benchmark for Audio TasksTuo Zhang, Tiantian Feng, Samiul Alam, and 4 more authorsIn IEEE International Conference on Acoustics, Speech, and Signal Processing, Aug 2023
Federated learning (FL) has gained substantial attention in recent years due to the data privacy concerns related to the pervasiveness of consumer devices that continuously collect data from users. While a number of FL benchmarks have been developed to facilitate FL research, none of them include audio data and audio-related tasks. In this paper, we fill this critical gap by introducing a new FL benchmark for audio tasks which we refer to as FedAudio. FedAudio includes four representative and commonly used audio datasets from three important audio tasks that are well aligned with FL use cases. In particular, a unique contribution of FedAudio is the introduction of data noises and label errors to the datasets to emulate challenges when deploying FL systems in real-world settings. FedAudio also includes the benchmark results of the datasets and a PyTorch library with the objective of facilitating researchers to fairly compare their algorithms. We hope FedAudio could act as a catalyst to inspire new FL research for audio tasks and thus benefit the acoustic and speech research community. The datasets and benchmark results can be accessed at this https URL.
2022
2022
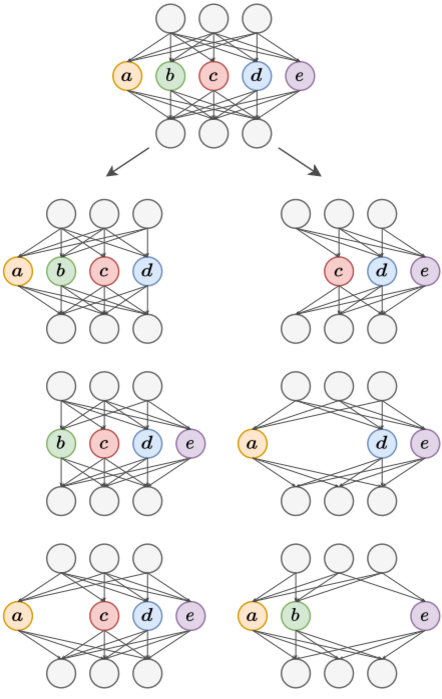 FedRolex: Model-Heterogeneous Federated Learning with Rolling Sub-Model ExtractionSamiul Alam, Luyang Liu, Ming Yan, and 1 more authorIn Advances in Neural Information Processing Systems, Aug 2022
FedRolex: Model-Heterogeneous Federated Learning with Rolling Sub-Model ExtractionSamiul Alam, Luyang Liu, Ming Yan, and 1 more authorIn Advances in Neural Information Processing Systems, Aug 2022Most cross-device federated learning (FL) studies focus on the model-homogeneous setting where the global server model and local client models are identical. However, such constraint not only excludes low-end clients who would otherwise make unique contributions to model training but also restrains clients from training large models due to on-device resource bottlenecks. In this work, we propose FedRolex, a partial training (PT)-based approach that enables model-heterogeneous FL and can train a global server model larger than the largest client model. At its core, FedRolex employs a rolling sub-model extraction scheme that allows different parts of the global server model to be evenly trained, which mitigates the client drift induced by the inconsistency between individual client models and server model architectures. Empirically, we show that FedRolex outperforms state-of-the-art PT-based model-heterogeneous FL methods (e.g. Federated Dropout) and reduces the gap between model-heterogeneous and model-homogeneous FL, especially under the large-model large-dataset regime. In addition, we provide theoretical statistical analysis on its advantage over Federated Dropout. Lastly, we evaluate FedRolex on an emulated real-world device distribution to show that FedRolex can enhance the inclusiveness of FL and boost the performance of low-end devices that would otherwise not benefit from FL. Our code is available at: https://github.com/AIoT-MLSys-Lab/FedRolex.
- FedSEA: A Semi-Asynchronous Federated Learning Framework for Extremely Heterogeneous DevicesJingwei Sun, Ang Li, Lin Duan, and 7 more authorsIn ACM Conference on Embedded Networked Sensor Systems, Dec 2022
Federated learning (FL) has attracted increasing attention as a promising technique to drive a vast number of edge devices with artificial intelligence. However, it is very challenging to guarantee the efficiency of a FL system in practice due to the heterogeneous computation resources on different devices. To improve the efficiency of FL systems in the real world, asynchronous FL (AFL) and semi-asynchronous FL (SAFL) methods are proposed such that the server does not need to wait for stragglers. However, existing AFL and SAFL systems suffer from poor accuracy and low efficiency in realistic settings where the data is non-IID distributed across devices and the on-device resources are extremely heterogeneous. In this work, we propose FedSEA - a semi-asynchronous FL framework for extremely heterogeneous devices. We theoretically disclose that the unbalanced aggregation frequency is a root cause of accuracy drop in SAFL. Based on this analysis, we design a training configuration scheduler to balance the aggregation frequency of devices such that the accuracy can be improved. To improve the efficiency of the system in realistic settings where the devices have dynamic on-device resource availability, we design a scheduler that can efficiently predict the arriving time of local updates from devices and adjust the synchronization time point according to the devices’ predicted arriving time. We also consider the extremely heterogeneous settings where there exist extremely lagging devices that take hundreds of times as long as the training time of the other devices. In the real world, there might be even some extreme stragglers which are not capable of training the global model. To enable these devices to join in training without impairing the systematic efficiency, Fed-SEA enables these extreme stragglers to conduct local training on much smaller models. Our experiments show that compared with status quo approaches, FedSEA improves the inference accuracy by 44.34% and reduces the systematic time cost and local training time cost by 87.02× and 792.9×. FedSEA also reduces the energy consumption of the devices with extremely limited resources by 752.9×
 Bengali Common Voice Speech Dataset for Automatic Speech RecognitionSamiul Alam, Asif Sushmit, Zaowad Abdullah, and 6 more authorsarXiv preprint arXiv:2206.14053, Dec 2022
Bengali Common Voice Speech Dataset for Automatic Speech RecognitionSamiul Alam, Asif Sushmit, Zaowad Abdullah, and 6 more authorsarXiv preprint arXiv:2206.14053, Dec 2022Bengali is one of the most spoken languages in the world with over 300 million speakers globally. Despite its popularity, research into the development of Bengali speech recognition systems is hindered due to the lack of diverse open-source datasets. As a way forward, we have crowdsourced the Bengali Common Voice Speech Dataset, which is a sentence-level automatic speech recognition corpus. Collected on the Mozilla Common Voice platform, the dataset is part of an ongoing campaign that has led to the collection of over 400 hours of data in 2 months and is growing rapidly. Our analysis shows that this dataset has more speaker, phoneme, and environmental diversity compared to the OpenSLR Bengali ASR dataset, the largest existing open-source Bengali speech dataset. We present insights obtained from the dataset and discuss key linguistic challenges that need to be addressed in future versions. Additionally, we report the current performance of a few Automatic Speech Recognition (ASR) algorithms and set a benchmark for future research.
2021
2021
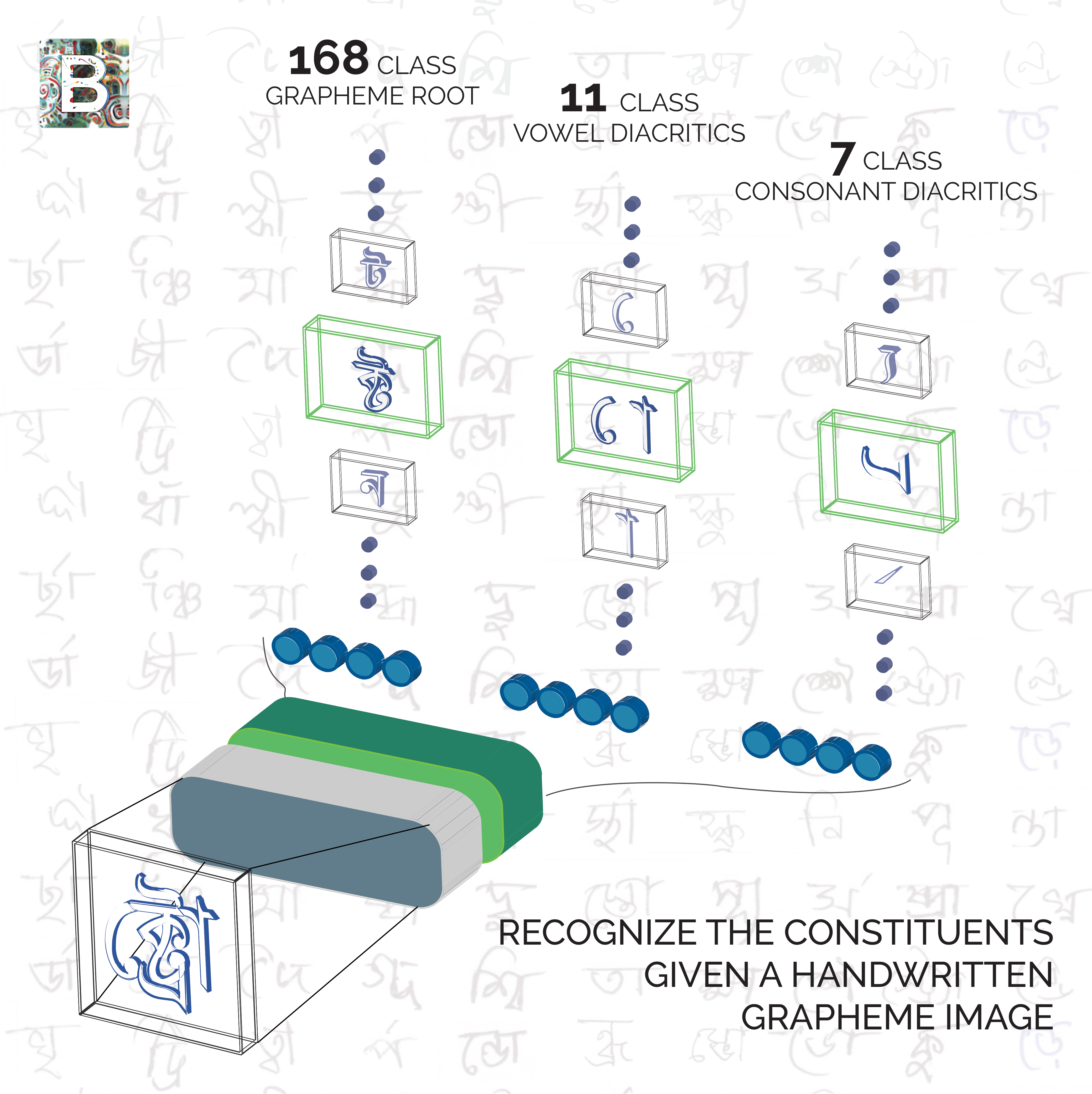 A large multi-target dataset of common bengali handwritten graphemesSamiul Alam, Tahsin Reasat, Asif Shahriyar Sushmit, and 4 more authorsDec 2021
A large multi-target dataset of common bengali handwritten graphemesSamiul Alam, Tahsin Reasat, Asif Shahriyar Sushmit, and 4 more authorsDec 2021Latin has historically led the state-of-the-art in handwritten optical character recognition (OCR) research. Adapting existing systems from Latin to alpha-syllabary languages is particularly challenging due to a sharp contrast between their orthographies. Due to a cursive writing system and frequent use of diacritics, the segmentation and/or alignment of graphical constituents with corresponding characters becomes significantly convoluted. We propose a labeling scheme based on graphemes (linguistic segments of word formation) that makes segmentation inside alpha-syllabary words linear and present the first dataset of Bengali handwritten graphemes that are commonly used in everyday context. The dataset contains 411k curated samples of 1295 unique commonly used Bengali graphemes. Additionally, the test set contains 900 uncommon Bengali graphemes for out of dictionary performance evaluation. The dataset is open-sourced as a part of a public Handwritten Grapheme Classification Challenge on Kaggle to benchmark vision algorithms for multi-target grapheme classification. The unique graphemes present in this dataset are selected based on commonality in the Google Bengali ASR corpus. From competition proceedings, we see that deep learning methods can generalize to a large span of out of dictionary graphemes which are absent during training (Kaggle Competition kaggle.com/c/bengaliai-cv19, Supplementary materials and Appendix https://github.com/AhmedImtiazPrio/ICDAR2021supplementary).
2018
2018
 Numtadb-assembled bengali handwritten digitsSamiul Alam, Tahsin Reasat, Rashed Mohammad Doha, and 1 more authorarXiv preprint arXiv:1806.02452, Dec 2018
Numtadb-assembled bengali handwritten digitsSamiul Alam, Tahsin Reasat, Rashed Mohammad Doha, and 1 more authorarXiv preprint arXiv:1806.02452, Dec 2018To benchmark Bengali digit recognition algorithms, a large publicly available dataset is required which is free from biases originating from geographical location, gender, and age. With this aim in mind, NumtaDB, a dataset consisting of more than 85,000 images of hand-written Bengali digits, has been assembled. This paper documents the collection and curation process of numerals along with the salient statistics of the dataset.
- AI Learns to Recognize Bengali Handwritten Digits: Bengali. AI Computer Vision Challenge 2018Sharif Amit Kamran, Ahmed Imtiaz Humayun, Samiul Alam, and 4 more authorsarXiv preprint arXiv:1810.04452, Dec 2018
 Predictive real-time beat tracking from music for embedded applicationIrfan Al-Hussaini, Ahmed Imtiaz Humayun, Samiul Alam, and 8 more authorsDec 2018
Predictive real-time beat tracking from music for embedded applicationIrfan Al-Hussaini, Ahmed Imtiaz Humayun, Samiul Alam, and 8 more authorsDec 2018Beat tracking from music signals has significant importance in multimedia information retrieval systems, especially in cover song detection. A predictive real-time beat tracking system can also be used to assist musicians performing live. In this paper we present a real-time beat tracking algorithm, fast enough to be implemented on an embedded system. The onset of a note is detected using a maximum filter approach that suppresses the effect of vibrato. Beats are predicted a second in advance using a causal variant of Dynamic Programming. We have employed an onset memoization algorithm, to reduce the computational resources required. Raspberry Pi was chosen as our preferred development board. We have demonstrated through experimental results that the proposed approach can satisfactorily estimate beat positions from a music signal in real-time with an average continuity score (AMLt) of 0.67.